
Hi, I'm Vilém (also Vilda), a PhD student at ETH Zürich, Switzerland. I'm passionate about natural language processing research, especially:
- Non-mainstream machine translation (quality estimation)
- NLP/MT evaluation (model-human communication, metrics)
- NLP-oriented human-computer interaction (confidence, annotations)
Serious publications
| Pitfalls and Outlooks in Using COMET |  WMT 2024 WMT 2024 |
papertoolcodevideo
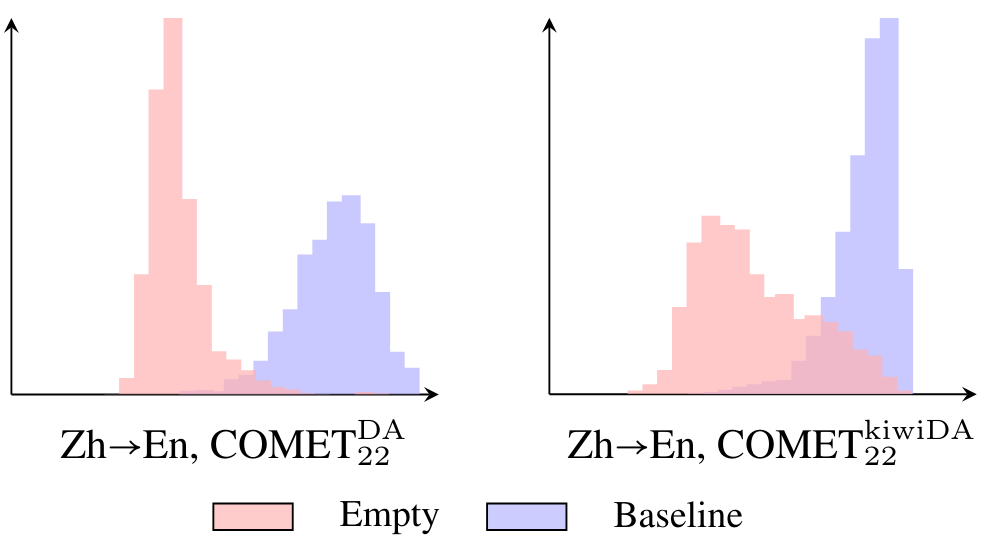
Since its introduction, the COMET metric has blazed a trail in the machine translation community, given its strong correlation with human judgements of translation quality. Its success stems from being a modified pre-trained multilingual model finetuned for quality assessment. However, it being a machine learning model also gives rise to a new set of pitfalls that may not be widely known. We investigate these unexpected behaviours from three aspects: 1) technical: obsolete software versions and compute precision; 2) data: empty content, language mismatch, and translationese at test time as well as distribution and domain biases in training; 3) usage and reporting: multi-reference support and model referencing in the literature. All of these problems imply that COMET scores is not comparable between papers or even technical setups and we put forward our perspective on fixing each issue. Furthermore, we release the SacreCOMET package that can generate a signature for the software and model configuration as well as an appropriate citation. The goal of this work is to help the community make more sound use of the COMET metric.
Since its introduction, the COMET metric has blazed a trail in the machine translation community, given its strong correlation with human judgements of translation quality. Its success stems from being a modified pre-trained multilingual model finetuned for quality assessment. However, it being a machine learning model also gives rise to a new set of pitfalls that may not be widely known. We investigate these unexpected behaviours from three aspects: 1) technical: obsolete software versions and compute precision; 2) data: empty content, language mismatch, and translationese at test time as well as distribution and domain biases in training; 3) usage and reporting: multi-reference support and model referencing in the literature. All of these problems imply that COMET scores is not comparable between papers or even technical setups and we put forward our perspective on fixing each issue. Furthermore, we release the SacreCOMET package that can generate a signature for the software and model configuration as well as an appropriate citation. The goal of this work is to help the community make more sound use of the COMET metric.
| Error Span Annotation: A Balanced Approach for Human Evaluation of Machine Translation | WMT 2024 |
papercode
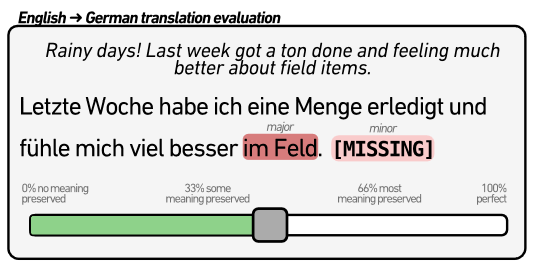
High-quality Machine Translation (MT) evaluation relies heavily on human judgments. Comprehensive error classification methods, such as Multidimensional Quality Metrics (MQM), are expensive as they are time-consuming and can only be done by experts, whose availability may be limited especially for low-resource languages. On the other hand, just assigning overall scores, like Direct Assessment (DA), is simpler and faster and can be done by translators of any level, but are less reliable. In this paper, we introduce Error Span Annotation (ESA), a human evaluation protocol which combines the continuous rating of DA with the high-level error severity span marking of MQM. We validate ESA by comparing it to MQM and DA for 12 MT systems and one human reference translation (English to German) from WMT23. The results show that ESA offers faster and cheaper annotations than MQM at the same quality level, without the requirement of expensive MQM experts.
High-quality Machine Translation (MT) evaluation relies heavily on human judgments. Comprehensive error classification methods, such as Multidimensional Quality Metrics (MQM), are expensive as they are time-consuming and can only be done by experts, whose availability may be limited especially for low-resource languages. On the other hand, just assigning overall scores, like Direct Assessment (DA), is simpler and faster and can be done by translators of any level, but are less reliable. In this paper, we introduce Error Span Annotation (ESA), a human evaluation protocol which combines the continuous rating of DA with the high-level error severity span marking of MQM. We validate ESA by comparing it to MQM and DA for 12 MT systems and one human reference translation (English to German) from WMT23. The results show that ESA offers faster and cheaper annotations than MQM at the same quality level, without the requirement of expensive MQM experts.
| Fine-Tuned Machine Translation Metrics Struggle in Unseen Domains | ACL 2024 |
paperdatacodevideo
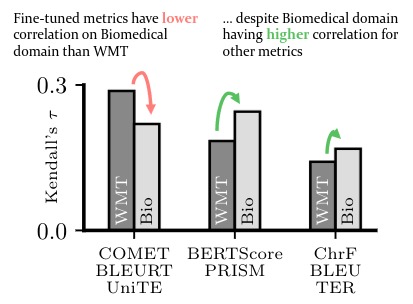
We introduce a new, extensive multidimensional quality metrics (MQM) annotated dataset covering 11 language pairs in the biomedical domain. We use this dataset to investigate whether machine translation (MT) metrics which are fine-tuned on human-generated MT quality judgements are robust to domain shifts between training and inference. We find that fine-tuned metrics exhibit a substantial performance drop in the unseen domain scenario relative to metrics that rely on the surface form, as well as pre-trained metrics which are not fine-tuned on MT quality judgments.
We introduce a new, extensive multidimensional quality metrics (MQM) annotated dataset covering 11 language pairs in the biomedical domain. We use this dataset to investigate whether machine translation (MT) metrics which are fine-tuned on human-generated MT quality judgements are robust to domain shifts between training and inference. We find that fine-tuned metrics exhibit a substantial performance drop in the unseen domain scenario relative to metrics that rely on the surface form, as well as pre-trained metrics which are not fine-tuned on MT quality judgments.
| Quality and Quantity of Machine Translation References for Automated Metrics | HumEval 2024 |
papercodevideo
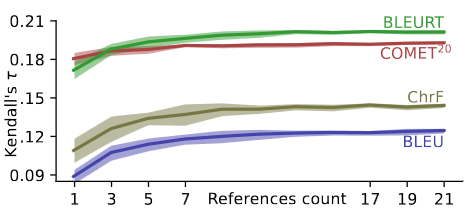
Automatic machine translation metrics often use human translations to determine the quality of system translations. Common wisdom in the field dictates that the human references should be of very high quality. However, there are no cost-benefit analyses that could be used to guide practitioners who plan to collect references for machine translation evaluation. We find that higher-quality references lead to better metric correlations with humans at the segment-level. Having up to 7 references per segment and taking their average helps all metrics. Interestingly, the references from vendors of different qualities can be mixed together and improve metric success. Higher quality references, however, cost more to create and we frame this as an optimization problem: given a specific budget, what references should be collected to maximize metric success. These findings can be used by evaluators of shared tasks when references need to be created under a certain budget.
Automatic machine translation metrics often use human translations to determine the quality of system translations. Common wisdom in the field dictates that the human references should be of very high quality. However, there are no cost-benefit analyses that could be used to guide practitioners who plan to collect references for machine translation evaluation. We find that higher-quality references lead to better metric correlations with humans at the segment-level. Having up to 7 references per segment and taking their average helps all metrics. Interestingly, the references from vendors of different qualities can be mixed together and improve metric success. Higher quality references, however, cost more to create and we frame this as an optimization problem: given a specific budget, what references should be collected to maximize metric success. These findings can be used by evaluators of shared tasks when references need to be created under a certain budget.
| WMT24 General Machine Translation Shared Task: The LLM Era is Here but MT is Not Solved Yet | WMT 2024 |
paperdata
This overview paper presents the results of the General Machine Translation Task organised as part of the 2024 Conference on Machine Translation (WMT). In the general MT task, participants were asked to build machine translation systems for any of 11 language pairs, to be evaluated on test sets consisting of three to five different domains. In addition to participating systems, we collected translations from 8 different large language models (LLMs) and 4 online translation providers. We evaluate system outputs with professional human annotators using a new protocol called Error Span Annotations (ESA).
This overview paper presents the results of the General Machine Translation Task organised as part of the 2024 Conference on Machine Translation (WMT). In the general MT task, participants were asked to build machine translation systems for any of 11 language pairs, to be evaluated on test sets consisting of three to five different domains. In addition to participating systems, we collected translations from 8 different large language models (LLMs) and 4 online translation providers. We evaluate system outputs with professional human annotators using a new protocol called Error Span Annotations (ESA).
| Navigating the Metrics Maze: Reconciling Score Magnitudes and Accuracies | ACL 2024 |
papercodedemotoolvideo
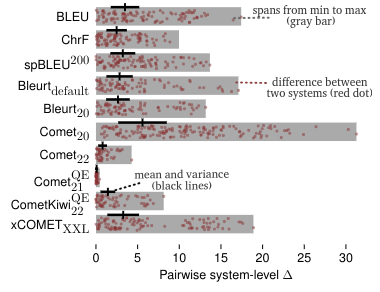
Ten years ago a single metric, BLEU, governed progress in machine translation research. For better or worse, there is no such consensus today, and consequently it is difficult for researchers to develop and retain the kinds of heuristic intuitions about metric deltas that drove earlier research and deployment decisions. This paper investigates the 'dynamic range' of a number of modern metrics in an effort to provide a collective understanding of the meaning of differences in scores both within and among metrics; in other words, we ask what point difference X in metric Y is required between two systems for humans to notice? We conduct our evaluation on a new large dataset, ToShip23, using it to discover deltas at which metrics achieve system-level differences that are meaningful to humans, which we measure by pairwise system accuracy. We additionally show that this method of establishing delta-accuracy is more stable than the standard use of statistical p-values in regards to testset size. Where data size permits, we also explore the effect of metric deltas and accuracy across finer-grained features such as translation direction, domain, and system closeness.
Ten years ago a single metric, BLEU, governed progress in machine translation research. For better or worse, there is no such consensus today, and consequently it is difficult for researchers to develop and retain the kinds of heuristic intuitions about metric deltas that drove earlier research and deployment decisions. This paper investigates the 'dynamic range' of a number of modern metrics in an effort to provide a collective understanding of the meaning of differences in scores both within and among metrics; in other words, we ask what point difference X in metric Y is required between two systems for humans to notice? We conduct our evaluation on a new large dataset, ToShip23, using it to discover deltas at which metrics achieve system-level differences that are meaningful to humans, which we measure by pairwise system accuracy. We additionally show that this method of establishing delta-accuracy is more stable than the standard use of statistical p-values in regards to testset size. Where data size permits, we also explore the effect of metric deltas and accuracy across finer-grained features such as translation direction, domain, and system closeness.
| RELIC: Investigating Large Language Model Responses using Self-Consistency | CHI 2024 |
papervideolink
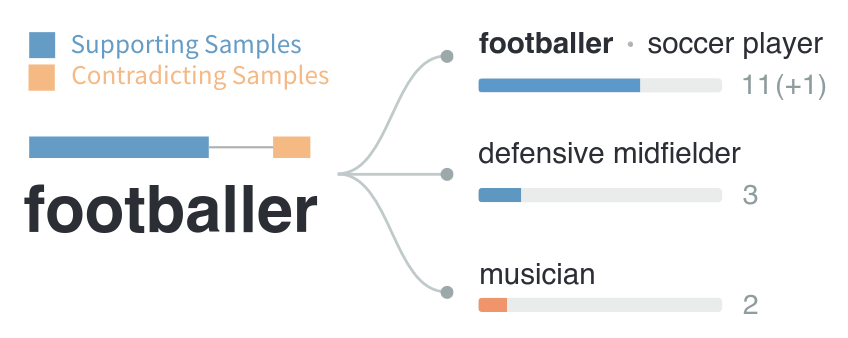
Large Language Models (LLMs) are notorious for blending fact with fiction and generating non-factual content, known as hallucinations. To tackle this challenge, we propose an interactive system that helps users obtain insights into the reliability of the generated text. Our approach is based on the idea that the self-consistency of multiple samples generated by the same LLM relates to its confidence in individual claims in the generated texts. Using this idea, we design RELIC, an interactive system that enables users to investigate and verify semantic-level variations in multiple long-form responses. This allows users to recognize potentially inaccurate information in the generated text and make necessary corrections. From a user study with ten participants, we demonstrate that our approach helps users better verify the reliability of the generated text. We further summarize the design implications and lessons learned from this research for inspiring future studies on reliable human-LLM interactions.
Large Language Models (LLMs) are notorious for blending fact with fiction and generating non-factual content, known as hallucinations. To tackle this challenge, we propose an interactive system that helps users obtain insights into the reliability of the generated text. Our approach is based on the idea that the self-consistency of multiple samples generated by the same LLM relates to its confidence in individual claims in the generated texts. Using this idea, we design RELIC, an interactive system that enables users to investigate and verify semantic-level variations in multiple long-form responses. This allows users to recognize potentially inaccurate information in the generated text and make necessary corrections. From a user study with ten participants, we demonstrate that our approach helps users better verify the reliability of the generated text. We further summarize the design implications and lessons learned from this research for inspiring future studies on reliable human-LLM interactions.
| AI-Assisted Human Evaluation of Machine Translation | In review 2024 |
papercode
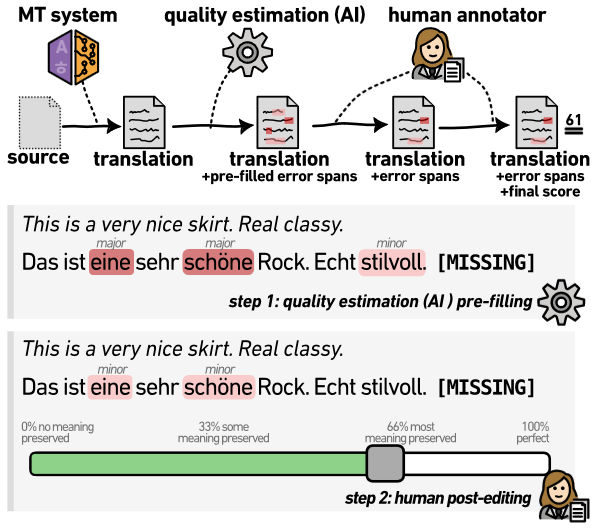
Annually, research teams spend large amounts of money to evaluate the quality of machine translation systems (WMT, inter alia). This is expensive because it requires detailed human labor. The recently proposed annotation protocol, Error Span Annotation (ESA), has annotators marking erroneous parts of the translation. In our work, we help the annotators by pre-filling the span annotations with automatic quality estimation. With AI assistance, we obtain more detailed annotations while cutting down the time per span annotation by half (71s/error span → 31s/error span). The biggest advantage of ESAAI protocol is an accurate priming of annotators (pre-filled error spans) before they assign the final score as opposed to starting from scratch. In addition, the annotation budget can be reduced by up to 24% with filtering of examples that the AI deems to be very likely to be correct.
Annually, research teams spend large amounts of money to evaluate the quality of machine translation systems (WMT, inter alia). This is expensive because it requires detailed human labor. The recently proposed annotation protocol, Error Span Annotation (ESA), has annotators marking erroneous parts of the translation. In our work, we help the annotators by pre-filling the span annotations with automatic quality estimation. With AI assistance, we obtain more detailed annotations while cutting down the time per span annotation by half (71s/error span → 31s/error span). The biggest advantage of ESAAI protocol is an accurate priming of annotators (pre-filled error spans) before they assign the final score as opposed to starting from scratch. In addition, the annotation budget can be reduced by up to 24% with filtering of examples that the AI deems to be very likely to be correct.
| A Bayesian Optimization Approach to Machine Translation Reranking | In review 2024 |
paper
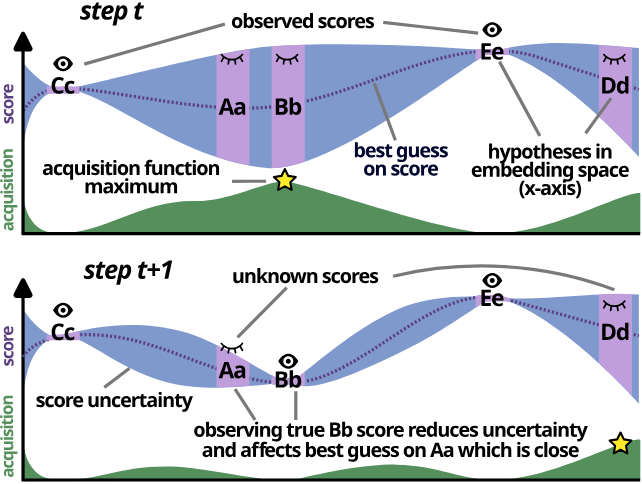
Reranking a list of candidates from a machine translation system with an external scoring model and returning the highest-scoring candidate remains a simple and effective method for improving the overall output quality. Translation scoring models continue to grow in size, with the best models being comparable to generation models. Thus, reranking can add substantial computational cost to the translation pipeline. In this work, we pose reranking as a Bayesian optimization (BayesOpt) problem. By strategically selecting candidates to score based on a balance of exploration and exploitation, we show that it is possible to find top-scoring candidates when scoring only a fraction of the candidate list. For instance, our method achieves the same CometKiwi score using only 70 scoring evaluations compared a baseline system using 180. We present a multi-fidelity setting for BayesOpt, where the candidates are first scored with a cheaper but noisier proxy scoring model, which further improves the cost-performance tradeoff when using smaller but well-trained distilled proxy scorers.
Reranking a list of candidates from a machine translation system with an external scoring model and returning the highest-scoring candidate remains a simple and effective method for improving the overall output quality. Translation scoring models continue to grow in size, with the best models being comparable to generation models. Thus, reranking can add substantial computational cost to the translation pipeline. In this work, we pose reranking as a Bayesian optimization (BayesOpt) problem. By strategically selecting candidates to score based on a balance of exploration and exploitation, we show that it is possible to find top-scoring candidates when scoring only a fraction of the candidate list. For instance, our method achieves the same CometKiwi score using only 70 scoring evaluations compared a baseline system using 180. We present a multi-fidelity setting for BayesOpt, where the candidates are first scored with a cheaper but noisier proxy scoring model, which further improves the cost-performance tradeoff when using smaller but well-trained distilled proxy scorers.
| Distributional Properties of Subword Regularization | EMNLP 2024 |
paper
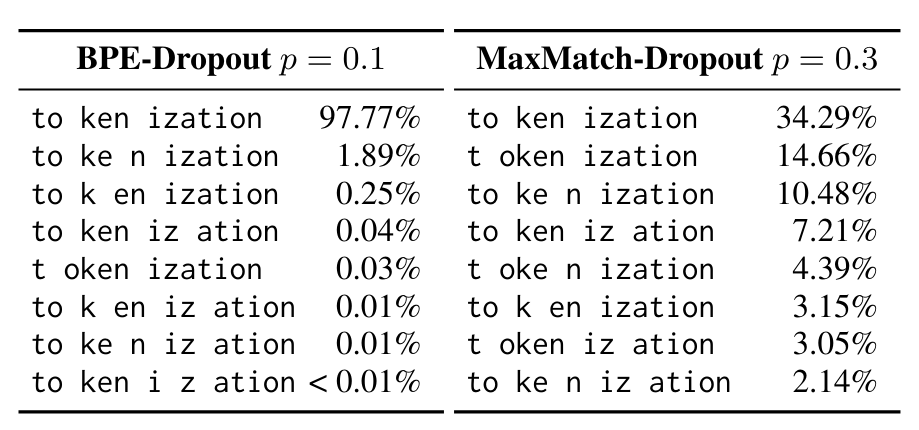
Subword regularization, used widely in NLP, improves model performance by reducing the dependency on exact tokenizations, augmenting the training corpus, and exposing the model to more unique contexts during training. BPE and MaxMatch, two popular subword tokenization schemes, have stochastic dropout regularization variants. However, there has not been an analysis of the distributions formed by them. We show that these stochastic variants are heavily biased towards a small set of tokenizations per word. If the benefits of subword regularization are as mentioned, we hypothesize that biasedness artificially limits the effectiveness of these schemes. Thus, we propose an algorithm to uniformly sample tokenizations that we use as a drop-in replacement for the stochastic aspects of existing tokenizers, and find that it improves machine translation quality.
Subword regularization, used widely in NLP, improves model performance by reducing the dependency on exact tokenizations, augmenting the training corpus, and exposing the model to more unique contexts during training. BPE and MaxMatch, two popular subword tokenization schemes, have stochastic dropout regularization variants. However, there has not been an analysis of the distributions formed by them. We show that these stochastic variants are heavily biased towards a small set of tokenizations per word. If the benefits of subword regularization are as mentioned, we hypothesize that biasedness artificially limits the effectiveness of these schemes. Thus, we propose an algorithm to uniformly sample tokenizations that we use as a drop-in replacement for the stochastic aspects of existing tokenizers, and find that it improves machine translation quality.
| A Diachronic Perspective on User Trust in AI under Uncertainty | EMNLP 2023 |
papercodedemovideodata
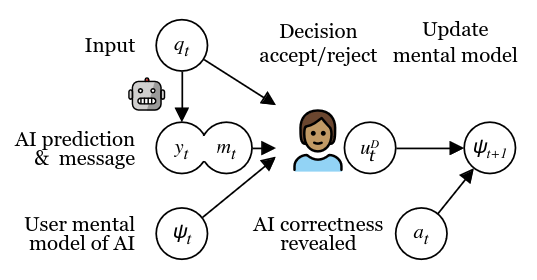
In human-AI collaboration, users typically form a mental model of the AI system, which captures the user’s beliefs about when the system performs well and when it does not. The construction of this mental model is guided by both the system’s veracity as well as the system output presented to the user e.g., the system’s confidence and an explanation for the prediction. However, modern NLP systems are seldom calibrated and are often confidently incorrect about their predictions, which violates users’ mental model and erodes their trust. In this work, we design a study where users bet on the correctness of an NLP system, and use it to study the evolution of user trust as a response to these trust-eroding events and how the user trust is rebuilt as a function of time after these events. We find that even a few highly inaccurate confidence estimation instances are enough to damage users’ trust in the system and performance, which does not easily recover over time. We further find that users are more forgiving to the NLP system if it is unconfidently correct rather than confidently incorrect, even though, from a game-theoretic perspective, their payoff is equivalent. Finally, we find that each user can entertain multiple mental models of the system based on the type of the question. These results highlight the importance of confidence calibration in developing user-centered NLP applications to avoid damaging user trust and compromising the collaboration performance.
In human-AI collaboration, users typically form a mental model of the AI system, which captures the user’s beliefs about when the system performs well and when it does not. The construction of this mental model is guided by both the system’s veracity as well as the system output presented to the user e.g., the system’s confidence and an explanation for the prediction. However, modern NLP systems are seldom calibrated and are often confidently incorrect about their predictions, which violates users’ mental model and erodes their trust. In this work, we design a study where users bet on the correctness of an NLP system, and use it to study the evolution of user trust as a response to these trust-eroding events and how the user trust is rebuilt as a function of time after these events. We find that even a few highly inaccurate confidence estimation instances are enough to damage users’ trust in the system and performance, which does not easily recover over time. We further find that users are more forgiving to the NLP system if it is unconfidently correct rather than confidently incorrect, even though, from a game-theoretic perspective, their payoff is equivalent. Finally, we find that each user can entertain multiple mental models of the system based on the type of the question. These results highlight the importance of confidence calibration in developing user-centered NLP applications to avoid damaging user trust and compromising the collaboration performance.
| WMT 2023 Shared Task on Machine Translation with Terminologies | EMNLP 2023 |
paperdatalink

The WMT 2023 Terminology Shared Task investigates progress in machine translation of texts with specialized vocabulary. The participants were given the source text and segment-level terminology dictionaries for three language pairs: Chinese→English, English→Czech, and German→English. We evaluate 21 submissions from 7 teams on two main criteria: general translation quality and the effectiveness of translating specialized terminology. Systems took varied approaches — incorporating terminology at inference time or weakly supervised training that uses terminology access. While incorporating terminology dictionaries leads to improvement in the translation quality, incorporating an equal amount of information from the reference leads to similar results. This challenges the position of terminologies being the crux of meaning in translation, it can also be explained by inadequate metrics which are not terminology-centric.
The WMT 2023 Terminology Shared Task investigates progress in machine translation of texts with specialized vocabulary. The participants were given the source text and segment-level terminology dictionaries for three language pairs: Chinese→English, English→Czech, and German→English. We evaluate 21 submissions from 7 teams on two main criteria: general translation quality and the effectiveness of translating specialized terminology. Systems took varied approaches — incorporating terminology at inference time or weakly supervised training that uses terminology access. While incorporating terminology dictionaries leads to improvement in the translation quality, incorporating an equal amount of information from the reference leads to similar results. This challenges the position of terminologies being the crux of meaning in translation, it can also be explained by inadequate metrics which are not terminology-centric.
| Tokenization and the Noiseless Channel | ACL 2023 |
papertoolvideo
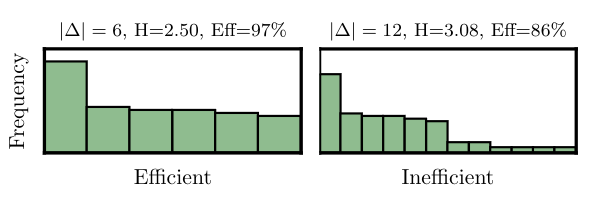
Subword tokenization is a key part of most NLP pipelines. However, little is known about why some tokenizer and hyperparameter combinations lead to improved downstream model performance over others. We propose that good tokenizers lead to efficient channel usage, where the channel is the means by which some input is conveyed to the model and efficiency can be quantified in information-theoretic terms as the ratio of the Shannon entropy to the maximum entropy of the subword distribution. Nevertheless, an optimal encoding according to Shannon entropy assigns extremely long codes to low-frequency subwords and very short codes to high-frequency subwords.Defining efficiency in terms of Rényi entropy, on the other hand, penalizes distributions with either very high or very low-frequency subwords.We posit that (1) extremely high-frequency subwords are problematic because their meaning is not distinct and (2) that low-frequency subwords may not appear frequently enough for their meaning to be learned properly; encodings that induce unigram distributions with either can harm model performance. In machine translation, we find that across multiple tokenizers, the Rényi entropy has a very strong correlation with BLEU: 0.82 in comparison to just -0.30 for compressed length.
Subword tokenization is a key part of most NLP pipelines. However, little is known about why some tokenizer and hyperparameter combinations lead to improved downstream model performance over others. We propose that good tokenizers lead to efficient channel usage, where the channel is the means by which some input is conveyed to the model and efficiency can be quantified in information-theoretic terms as the ratio of the Shannon entropy to the maximum entropy of the subword distribution. Nevertheless, an optimal encoding according to Shannon entropy assigns extremely long codes to low-frequency subwords and very short codes to high-frequency subwords.Defining efficiency in terms of Rényi entropy, on the other hand, penalizes distributions with either very high or very low-frequency subwords.We posit that (1) extremely high-frequency subwords are problematic because their meaning is not distinct and (2) that low-frequency subwords may not appear frequently enough for their meaning to be learned properly; encodings that induce unigram distributions with either can harm model performance. In machine translation, we find that across multiple tokenizers, the Rényi entropy has a very strong correlation with BLEU: 0.82 in comparison to just -0.30 for compressed length.
| A Formal Perspective on Byte-Pair Encoding | ACL 2023 |
papercodevideo
Byte-Pair Encoding (BPE) is a popular algorithm used for tokenizing data in NLP, despite being devised initially as a compression method. BPE appears to be a greedy algorithm at face value, but the underlying optimization problem that BPE seeks to solve has not yet been laid down. We formalize BPE as a combinatorial optimization problem. Via submodular functions, we prove that the iterative greedy version is a 1/sigma*(1-e(-sigma))-approximation of an optimal merge sequence, where sigma is the total backward curvature with respect to the optimal merge sequence. Empirically the lower bound of the approximation is ~0.37.We provide a faster implementation of BPE which improves the runtime complexity from O(NM) to O(N log M), where N is the sequence length and M is the merge count. Finally, we optimize the brute-force algorithm for optimal BPE using memoization.
Byte-Pair Encoding (BPE) is a popular algorithm used for tokenizing data in NLP, despite being devised initially as a compression method. BPE appears to be a greedy algorithm at face value, but the underlying optimization problem that BPE seeks to solve has not yet been laid down. We formalize BPE as a combinatorial optimization problem. Via submodular functions, we prove that the iterative greedy version is a 1/sigma*(1-e(-sigma))-approximation of an optimal merge sequence, where sigma is the total backward curvature with respect to the optimal merge sequence. Empirically the lower bound of the approximation is ~0.37.We provide a faster implementation of BPE which improves the runtime complexity from O(NM) to O(N log M), where N is the sequence length and M is the merge count. Finally, we optimize the brute-force algorithm for optimal BPE using memoization.
| Evaluating Optimal Reference Translations | JNLE 2024 |
papercodedata
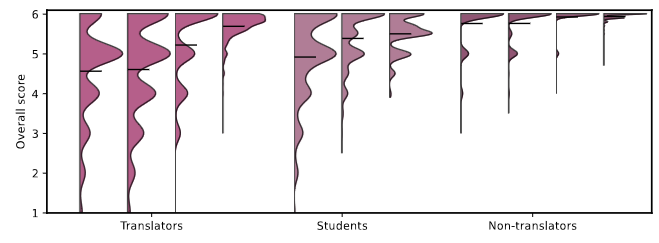
The overall translation quality reached by current machine translation (MT) systems for high-resourced language pairs is remarkably good. Standard methods of evaluation are not suitable nor intended to uncover the many translation errors and quality deficiencies that still persist. Furthermore, the quality of standard reference translations is commonly questioned and comparable quality levels have been reached by MT alone in several language pairs. Navigating further research in these high-resource settings is thus difficult. In this article, we propose a methodology for creating more reliable document-level human reference translations, called 'optimal reference translations,' with the simple aim to raise the bar of what should be deemed 'human translation quality.' We evaluate the obtained document-level optimal reference translations in comparison with 'standard' ones, confirming a significant quality increase and also documenting the relationship between evaluation and translation editing.
The overall translation quality reached by current machine translation (MT) systems for high-resourced language pairs is remarkably good. Standard methods of evaluation are not suitable nor intended to uncover the many translation errors and quality deficiencies that still persist. Furthermore, the quality of standard reference translations is commonly questioned and comparable quality levels have been reached by MT alone in several language pairs. Navigating further research in these high-resource settings is thus difficult. In this article, we propose a methodology for creating more reliable document-level human reference translations, called 'optimal reference translations,' with the simple aim to raise the bar of what should be deemed 'human translation quality.' We evaluate the obtained document-level optimal reference translations in comparison with 'standard' ones, confirming a significant quality increase and also documenting the relationship between evaluation and translation editing.
| Re-visiting Automated Topic Model Evaluation with Large Language Models | EMNLP 2023 |
papervideocode
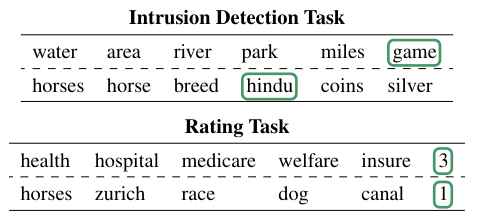
Topic models help us make sense of large text collections. Automatically evaluating their output and determining the optimal number of topics are both longstanding challenges, with no effective automated solutions to date. This paper proposes using large language models (LLMs) for these tasks. We find that LLMs appropriately assess the resulting topics, correlating more strongly with human judgments than existing automated metrics. However, the setup of the evaluation task is crucial — LLMs perform better on coherence ratings of word sets than on intrustion detection. We find that LLMs can also assist us in guiding us towards a reasonable number of topics. In actual applications, topic models are typically used to answer a research question related to a collection of texts. We can incorporate this research question in the prompt to the LLM, which helps estimating the optimal number of topics.
Topic models help us make sense of large text collections. Automatically evaluating their output and determining the optimal number of topics are both longstanding challenges, with no effective automated solutions to date. This paper proposes using large language models (LLMs) for these tasks. We find that LLMs appropriately assess the resulting topics, correlating more strongly with human judgments than existing automated metrics. However, the setup of the evaluation task is crucial — LLMs perform better on coherence ratings of word sets than on intrustion detection. We find that LLMs can also assist us in guiding us towards a reasonable number of topics. In actual applications, topic models are typically used to answer a research question related to a collection of texts. We can incorporate this research question in the prompt to the LLM, which helps estimating the optimal number of topics.
| Interactive Analysis of LLMs using Meaningful Counterfactuals | In review 2024 |
paper
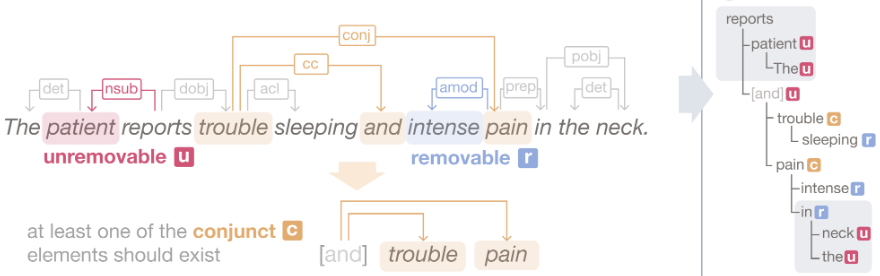
Counterfactual examples are useful for exploring the decision boundaries of machine learning models and determining feature attributions. How can we apply counterfactual-based methods to analyze and explain LLMs? We identify the following key challenges. First, the generated textual counterfactuals should be meaningful and readable to users and thus can be mentally compared to draw conclusions. Second, to make the solution scalable to long-form text, users should be equipped with tools to create batches of counterfactuals from perturbations at various granularity levels and interactively analyze the results. In this paper, we tackle the above challenges and contribute 1) a novel algorithm for generating batches of complete and meaningful textual counterfactuals by removing and replacing text segments in different granularities, and 2) LLM Analyzer, an interactive visualization tool to help users understand an LLM's behaviors by interactively inspecting and aggregating meaningful counterfactuals. We evaluate the proposed algorithm by the grammatical correctness of its generated counterfactuals using 1,000 samples from medical, legal, finance, education, and news datasets. In our experiments, 97.2% of the counterfactuals are grammatically correct. Through a use case, user studies, and feedback from experts, we demonstrate the usefulness and usability of the proposed interactive visualization tool.
Counterfactual examples are useful for exploring the decision boundaries of machine learning models and determining feature attributions. How can we apply counterfactual-based methods to analyze and explain LLMs? We identify the following key challenges. First, the generated textual counterfactuals should be meaningful and readable to users and thus can be mentally compared to draw conclusions. Second, to make the solution scalable to long-form text, users should be equipped with tools to create batches of counterfactuals from perturbations at various granularity levels and interactively analyze the results. In this paper, we tackle the above challenges and contribute 1) a novel algorithm for generating batches of complete and meaningful textual counterfactuals by removing and replacing text segments in different granularities, and 2) LLM Analyzer, an interactive visualization tool to help users understand an LLM's behaviors by interactively inspecting and aggregating meaningful counterfactuals. We evaluate the proposed algorithm by the grammatical correctness of its generated counterfactuals using 1,000 samples from medical, legal, finance, education, and news datasets. In our experiments, 97.2% of the counterfactuals are grammatically correct. Through a use case, user studies, and feedback from experts, we demonstrate the usefulness and usability of the proposed interactive visualization tool.
| PWESuite: Phonetic Word Embeddings and Tasks They Facilitate | LREC-COLING 2024 |
papercodedatavideo

Word embeddings that map words into a fixed-dimensional vector space are the backbone of modern NLP. Most word embedding methods encode semantic information. However, phonetic information, which is important for some tasks, is often overlooked. In this work, we develop several novel methods which leverage articulatory features to build phonetically informed word embeddings, and present a set of phonetic word embeddings to encourage their community development, evaluation and use. While several methods for learning phonetic word embeddings already exist, there is a lack of consistency in evaluating their effectiveness. Thus, we also proposes several ways to evaluate both intrinsic aspects of phonetic word embeddings, such as word retrieval and correlation with sound similarity, and extrinsic performances, such as rhyme and cognate detection and sound analogies. We hope that our suite of tasks will promote reproducibility and provide direction for future research on phonetic word embeddings.
Word embeddings that map words into a fixed-dimensional vector space are the backbone of modern NLP. Most word embedding methods encode semantic information. However, phonetic information, which is important for some tasks, is often overlooked. In this work, we develop several novel methods which leverage articulatory features to build phonetically informed word embeddings, and present a set of phonetic word embeddings to encourage their community development, evaluation and use. While several methods for learning phonetic word embeddings already exist, there is a lack of consistency in evaluating their effectiveness. Thus, we also proposes several ways to evaluate both intrinsic aspects of phonetic word embeddings, such as word retrieval and correlation with sound similarity, and extrinsic performances, such as rhyme and cognate detection and sound analogies. We hope that our suite of tasks will promote reproducibility and provide direction for future research on phonetic word embeddings.
| Two Counterexamples to Tokenization and the Noiseless Channel | LREC-COLING 2024 |
paper
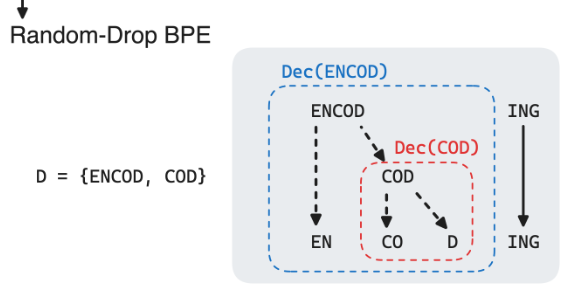
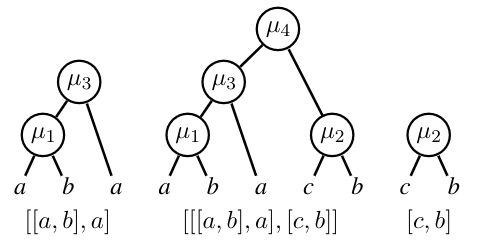
In Tokenization and the Noiseless Channel, Rényi efficiency is suggested as an intrinsic mechanism for evaluating a tokenizer: for NLP tasks, the tokenizer which leads to the highest Rényi efficiency of the unigram distribution should be chosen. The Rényi efficiency is thus treated as a predictor of downstream performance (e.g., predicting BLEU for machine translation task), without the expensive step of training multiple models with different tokenizers. Although useful, the predictive power of this metric is not perfect, and the authors note there are additional qualities of a good tokenization scheme that Rényi efficiency alone cannot capture. We describe two variants of BPE tokenization which can arbitrarily increase Rényi efficiency while decreasing the downstream model performance. These counterexamples expose cases where Rényi efficiency fails as an intrinsic tokenization metric and thus give insight for building more accurate predictors.
In Tokenization and the Noiseless Channel, Rényi efficiency is suggested as an intrinsic mechanism for evaluating a tokenizer: for NLP tasks, the tokenizer which leads to the highest Rényi efficiency of the unigram distribution should be chosen. The Rényi efficiency is thus treated as a predictor of downstream performance (e.g., predicting BLEU for machine translation task), without the expensive step of training multiple models with different tokenizers. Although useful, the predictive power of this metric is not perfect, and the authors note there are additional qualities of a good tokenization scheme that Rényi efficiency alone cannot capture. We describe two variants of BPE tokenization which can arbitrarily increase Rényi efficiency while decreasing the downstream model performance. These counterexamples expose cases where Rényi efficiency fails as an intrinsic tokenization metric and thus give insight for building more accurate predictors.
| Poor Man's Quality Estimation: Predicting Ref.-Based MT Metrics Without Reference | EACL 2023 |
papercodevideo
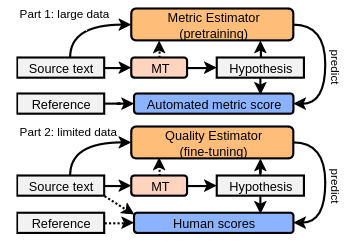
Machine translation quality estimation (QE) predicts human judgements of a translation hypothesis without seeing the reference. State-of-the-art QE systems based on pretrained language models have been achieving remarkable correlations with human judgements yet they are computationally heavy and require human annotations, which are slow and expensive to create. To address these limitations, we define the problem of metric estimation (ME) where one predicts the automated metric scores also without the reference. We show that even without access to the reference, our model can estimate automated metrics (ρ = 60% for BLEU, ρ = 51% for other metrics) at the sentence-level. Because automated metrics correlate with human judgements, we can leverage the ME task for pre-training a QE model. For the QE task, we find that pre-training on TER is better (ρ = 23%) than training for scratch (ρ = 20%).
Machine translation quality estimation (QE) predicts human judgements of a translation hypothesis without seeing the reference. State-of-the-art QE systems based on pretrained language models have been achieving remarkable correlations with human judgements yet they are computationally heavy and require human annotations, which are slow and expensive to create. To address these limitations, we define the problem of metric estimation (ME) where one predicts the automated metric scores also without the reference. We show that even without access to the reference, our model can estimate automated metrics (ρ = 60% for BLEU, ρ = 51% for other metrics) at the sentence-level. Because automated metrics correlate with human judgements, we can leverage the ME task for pre-training a QE model. For the QE task, we find that pre-training on TER is better (ρ = 23%) than training for scratch (ρ = 20%).
| Neural Machine Translation Quality and Post-Editing Performance | EMNLP 2021 |
papercodevideodata
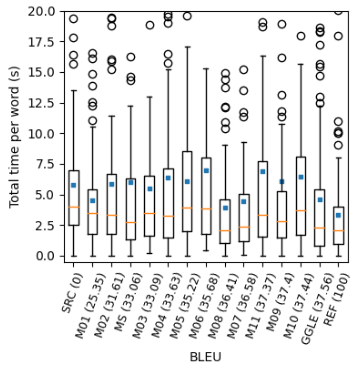
We test the natural expectation that using MT in professional translation saves human processing time. The last such study was carried out by Sanchez-Torron and Koehn (2016) with phrase-based MT, artificially reducing the translation quality. In contrast, we focus on neural MT (NMT) of high quality, which has become the state-of-the-art approach since then and also got adopted by most translation companies. Through an experimental study involving over 30 professional translators for English -> Czech translation, we examine the relationship between NMT performance and post-editing time and quality. Across all models, we found that better MT systems indeed lead to fewer changes in the sentences in this industry setting. The relation between system quality and post-editing time is however not straightforward and, contrary to the results on phrase-based MT, BLEU is definitely not a stable predictor of the time or final output quality.
We test the natural expectation that using MT in professional translation saves human processing time. The last such study was carried out by Sanchez-Torron and Koehn (2016) with phrase-based MT, artificially reducing the translation quality. In contrast, we focus on neural MT (NMT) of high quality, which has become the state-of-the-art approach since then and also got adopted by most translation companies. Through an experimental study involving over 30 professional translators for English -> Czech translation, we examine the relationship between NMT performance and post-editing time and quality. Across all models, we found that better MT systems indeed lead to fewer changes in the sentences in this industry setting. The relation between system quality and post-editing time is however not straightforward and, contrary to the results on phrase-based MT, BLEU is definitely not a stable predictor of the time or final output quality.
| Providing Backtranslation Improves Users Confidence in MT, Not Quality | NAACL 2021 |
papercodevideo
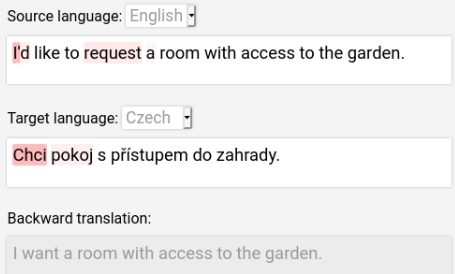
Translating text into a language unknown to the text’s author, dubbed outbound translation, is a modern need for which the user experience has significant room for improvement, beyond the basic machine translation facility. We demonstrate this by showing three ways in which user confidence in the outbound translation, as well as its overall final quality, can be affected: backward translation, quality estimation (with alignment) and source paraphrasing. In this paper, we describe an experiment on outbound translation from English to Czech and Estonian. We examine the effects of each proposed feedback module and further focus on how the quality of machine translation systems influence these findings and the user perception of success. We show that backward translation feedback has a mixed effect on the whole process: it increases user confidence in the produced translation, but not the objective quality.
Translating text into a language unknown to the text’s author, dubbed outbound translation, is a modern need for which the user experience has significant room for improvement, beyond the basic machine translation facility. We demonstrate this by showing three ways in which user confidence in the outbound translation, as well as its overall final quality, can be affected: backward translation, quality estimation (with alignment) and source paraphrasing. In this paper, we describe an experiment on outbound translation from English to Czech and Estonian. We examine the effects of each proposed feedback module and further focus on how the quality of machine translation systems influence these findings and the user perception of success. We show that backward translation feedback has a mixed effect on the whole process: it increases user confidence in the produced translation, but not the objective quality.
| WMT20 Document-Level Markable Error Exploration | WMT 2020 |
papercodedata
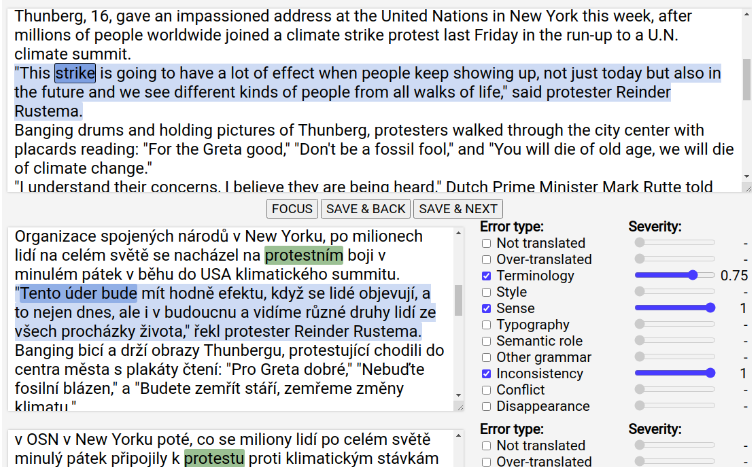
Even though sentence-centric metrics are used widely in machine translation evaluation, document-level performance is at least equally important for professional usage. In this paper, we bring attention to detailed document-level evaluation focused on markables (expressions bearing most of the document meaning) and the negative impact of various markable error phenomena on the translation. For an annotation experiment of two phases, we chose Czech and English documents translated by systems submitted to WMT20 News Translation Task. These documents are from the News, Audit and Lease domains. We show that the quality and also the kind of errors varies significantly among the domains. This systematic variance is in contrast to the automatic evaluation results. We inspect which specific markables are problematic for MT systems and conclude with an analysis of the effect of markable error types on the MT performance measured by humans and automatic evaluation tools.
Even though sentence-centric metrics are used widely in machine translation evaluation, document-level performance is at least equally important for professional usage. In this paper, we bring attention to detailed document-level evaluation focused on markables (expressions bearing most of the document meaning) and the negative impact of various markable error phenomena on the translation. For an annotation experiment of two phases, we chose Czech and English documents translated by systems submitted to WMT20 News Translation Task. These documents are from the News, Audit and Lease domains. We show that the quality and also the kind of errors varies significantly among the domains. This systematic variance is in contrast to the automatic evaluation results. We inspect which specific markables are problematic for MT systems and conclude with an analysis of the effect of markable error types on the MT performance measured by humans and automatic evaluation tools.
Less-serious projects
| Knowledge Base Index Compression via Dimensionality and Precision Reduction | SpaNLP 2022 |
papercodevideo
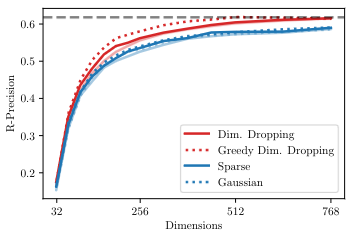
Recently neural network based approaches to knowledge-intensive NLP tasks, such as question answering, started to rely heavily on the combination of neural retrievers and readers. Retrieval is typically performed over a large textual knowledge base (KB) which requires significant memory and compute resources, especially when scaled up. On HotpotQA we systematically investigate reducing the size of the KB index by means of dimensionality (sparse random projections, PCA, autoencoders) and numerical precision reduction. Our results show that PCA is an easy solution that requires very little data and is only slightly worse than autoencoders, which are less stable. All methods are sensitive to pre- and post-processing and data should always be centered and normalized both before and after dimension reduction. Finally, we show that it is possible to combine PCA with using 1bit per dimension. Overall we achieve (1) 100× compression with 75%, and (2) 24× compression with 92% original retrieval performance.
Recently neural network based approaches to knowledge-intensive NLP tasks, such as question answering, started to rely heavily on the combination of neural retrievers and readers. Retrieval is typically performed over a large textual knowledge base (KB) which requires significant memory and compute resources, especially when scaled up. On HotpotQA we systematically investigate reducing the size of the KB index by means of dimensionality (sparse random projections, PCA, autoencoders) and numerical precision reduction. Our results show that PCA is an easy solution that requires very little data and is only slightly worse than autoencoders, which are less stable. All methods are sensitive to pre- and post-processing and data should always be centered and normalized both before and after dimension reduction. Finally, we show that it is possible to combine PCA with using 1bit per dimension. Overall we achieve (1) 100× compression with 75%, and (2) 24× compression with 92% original retrieval performance.
| Sampling and Filtering of Neural Machine Translation Distillation Data | NAACL SRW 2021 |
papercode
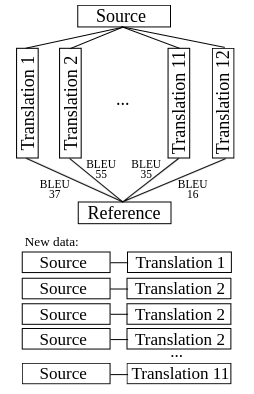
In most of neural machine translation distillation or stealing scenarios, the highest-scoring hypothesis of the target model (teacher) is used to train a new model (student). If reference translations are also available, then better hypotheses (with respect to the references) can be oversampled and poor hypotheses either removed or undersampled. This paper explores the sampling method landscape (pruning, hypothesis oversampling and undersampling, deduplication and their combination) with English to Czech and English to German MT models using standard MT evaluation metrics. We show that careful oversampling and combination with the original data leads to better performance when compared to training only on the original or synthesized data or their direct combination.
In most of neural machine translation distillation or stealing scenarios, the highest-scoring hypothesis of the target model (teacher) is used to train a new model (student). If reference translations are also available, then better hypotheses (with respect to the references) can be oversampled and poor hypotheses either removed or undersampled. This paper explores the sampling method landscape (pruning, hypothesis oversampling and undersampling, deduplication and their combination) with English to Czech and English to German MT models using standard MT evaluation metrics. We show that careful oversampling and combination with the original data leads to better performance when compared to training only on the original or synthesized data or their direct combination.
| Harmonizing Assistance: Moderating Visual andTextual Aids in AI-Enhanced Textbook Readingwith IRead | In review 2024 |
paper
Textbooks continue to be one of primary mediums of learning. Students often need additional support during the process of reading textbooks leading to several research efforts that aim to increase student engagement and provide tailored experiences in textbook reading. However, providing excessive information beyond the textbook can also distract students from the reading task. When enhancing the reading experience, one has to strike a delicate balance between providing sufficient informational support and maintaining students’ focus on textbook reading. Fusing together latest developments in large language models (LLMs), their applications in education and several pedagogical theories, we design a textbook reading guidance mechanism. We introduce IRead, an interactive tool for textbook reading which uses LLMs with visualization and interaction techniques, to enhance students’ reading and learning experiences. IRead incorporates conceptual visualizations that reflect the textbook’s content and features an AI-driven question bot that generates questions and offers hints in response to student reading and interaction history. We evaluate IRead with a between-subject user study and measure the effectiveness of our methodology in supporting the students’ reading experience based on the Bloom’s Taxonomy and the ARCS model. We collect feedback from participants ranging from undergraduate to doctorate students. The results highlight the effectiveness of simple yet intuitive visualizations, such as the concept tree in IRead. We also derive general insights for the development of tools that enhance educational reading experiences.
Textbooks continue to be one of primary mediums of learning. Students often need additional support during the process of reading textbooks leading to several research efforts that aim to increase student engagement and provide tailored experiences in textbook reading. However, providing excessive information beyond the textbook can also distract students from the reading task. When enhancing the reading experience, one has to strike a delicate balance between providing sufficient informational support and maintaining students’ focus on textbook reading. Fusing together latest developments in large language models (LLMs), their applications in education and several pedagogical theories, we design a textbook reading guidance mechanism. We introduce IRead, an interactive tool for textbook reading which uses LLMs with visualization and interaction techniques, to enhance students’ reading and learning experiences. IRead incorporates conceptual visualizations that reflect the textbook’s content and features an AI-driven question bot that generates questions and offers hints in response to student reading and interaction history. We evaluate IRead with a between-subject user study and measure the effectiveness of our methodology in supporting the students’ reading experience based on the Bloom’s Taxonomy and the ARCS model. We collect feedback from participants ranging from undergraduate to doctorate students. The results highlight the effectiveness of simple yet intuitive visualizations, such as the concept tree in IRead. We also derive general insights for the development of tools that enhance educational reading experiences.
| How to Engage Your Readers? Generating Guiding Questions to Promote Active Reading | ACL 2024 |
papercode

Using questions in written text is an effective strategy to enhance readability. However, what makes an active reading question good, what the linguistic role of these questions is, and what is their impact on human reading remains understudied. We introduce GuidingQ, a dataset of 10K in-text questions from textbooks and scientific articles. By analyzing the dataset, we present a comprehensive understanding of the use, distribution, and linguistic characteristics of these questions. Then, we explore various approaches to generate such questions using language models. Our results highlight the importance of capturing inter-question relationships and the challenge of question position identification in generating these questions. Finally, we conduct a human study to understand the implication of such questions on reading comprehension. We find that the generated questions are of high quality and are almost as effective as human-written questions in terms of improving readers' memorization and comprehension.
Using questions in written text is an effective strategy to enhance readability. However, what makes an active reading question good, what the linguistic role of these questions is, and what is their impact on human reading remains understudied. We introduce GuidingQ, a dataset of 10K in-text questions from textbooks and scientific articles. By analyzing the dataset, we present a comprehensive understanding of the use, distribution, and linguistic characteristics of these questions. Then, we explore various approaches to generate such questions using language models. Our results highlight the importance of capturing inter-question relationships and the challenge of question position identification in generating these questions. Finally, we conduct a human study to understand the implication of such questions on reading comprehension. We find that the generated questions are of high quality and are almost as effective as human-written questions in terms of improving readers' memorization and comprehension.
| Scaling the Authoring of AutoTutors with Large Language Models | Learning@Scale 2024 |
paper
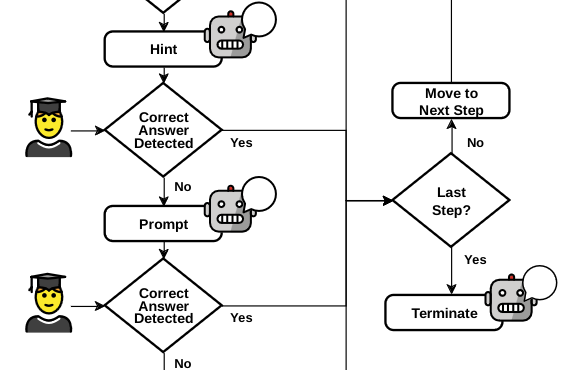
Large Language Models (LLMs) have found several use cases in education, ranging from automatic question generation to essay evaluation. In this paper, we explore the potential of using Large Language Models (LLMs) to author Intelligent Tutoring Systems. A common pitfall of LLMs is their straying from desired pedagogical strategies such as leaking the answer to the student, and in general, providing no guarantees. We posit that while LLMs with certain guardrails can take the place of subject experts, the overall pedagogical design still needs to be handcrafted for the best learning results. Based on this principle, we create a sample end-to-end tutoring system named MWPTutor, which uses LLMs to fill in the state space of a pre-defined finite state transducer. This approach retains the structure and the pedagogy of traditional tutoring systems that has been developed over the years by learning scientists but brings in additional flexibility of LLM-based approaches. Through a human evaluation study on two datasets based on math word problems, we show that our hybrid approach achieves a better overall tutoring score than an instructed, but otherwise free-form, GPT-4. MWPTutor is completely modular and opens up the scope for the community to improve its performance by improving individual modules or using different teaching strategies that it can follow.
Large Language Models (LLMs) have found several use cases in education, ranging from automatic question generation to essay evaluation. In this paper, we explore the potential of using Large Language Models (LLMs) to author Intelligent Tutoring Systems. A common pitfall of LLMs is their straying from desired pedagogical strategies such as leaking the answer to the student, and in general, providing no guarantees. We posit that while LLMs with certain guardrails can take the place of subject experts, the overall pedagogical design still needs to be handcrafted for the best learning results. Based on this principle, we create a sample end-to-end tutoring system named MWPTutor, which uses LLMs to fill in the state space of a pre-defined finite state transducer. This approach retains the structure and the pedagogy of traditional tutoring systems that has been developed over the years by learning scientists but brings in additional flexibility of LLM-based approaches. Through a human evaluation study on two datasets based on math word problems, we show that our hybrid approach achieves a better overall tutoring score than an instructed, but otherwise free-form, GPT-4. MWPTutor is completely modular and opens up the scope for the community to improve its performance by improving individual modules or using different teaching strategies that it can follow.
| Enhancing Textbooks with Visuals from the Web for Improved Learning | EMNLP 2023 |
papercodevideo
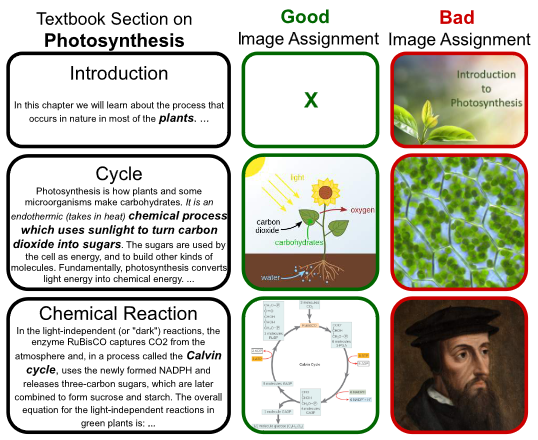
Textbooks are one of the main mediums for delivering high-quality education to students. In particular, explanatory and illustrative visuals play a key role in retention, comprehension and general transfer of knowledge. However, many textbooks lack these interesting visuals to support student learning. In this paper, we investigate the effectiveness of vision-language models to automatically enhance textbooks with images from the web. We collect a dataset of e-textbooks in the math, science, social science and business domains. We then set up a text-image matching task that involves retrieving and appropriately assigning web images to textbooks, which we frame as a matching optimization problem. Through a crowd-sourced evaluation, we verify that (1) while the original textbook images are rated higher, automatically assigned ones are not far behind, and (2) the precise formulation of the optimization problem matters. We release the dataset of textbooks with an associated image bank to inspire further research in this intersectional area of computer vision and NLP for education.
Textbooks are one of the main mediums for delivering high-quality education to students. In particular, explanatory and illustrative visuals play a key role in retention, comprehension and general transfer of knowledge. However, many textbooks lack these interesting visuals to support student learning. In this paper, we investigate the effectiveness of vision-language models to automatically enhance textbooks with images from the web. We collect a dataset of e-textbooks in the math, science, social science and business domains. We then set up a text-image matching task that involves retrieving and appropriately assigning web images to textbooks, which we frame as a matching optimization problem. Through a crowd-sourced evaluation, we verify that (1) while the original textbook images are rated higher, automatically assigned ones are not far behind, and (2) the precise formulation of the optimization problem matters. We release the dataset of textbooks with an associated image bank to inspire further research in this intersectional area of computer vision and NLP for education.
| Shrinking Knowledge Base Size: Dimension Reduction, Splitting & Filtering | Master thesis 2022 |
linkcode
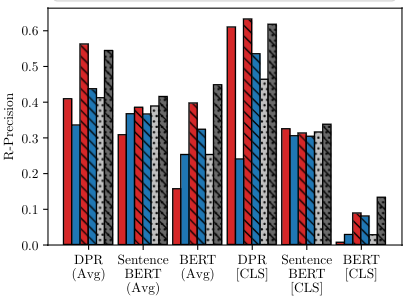
ecently neural network based approaches to knowledge-intensive NLP tasks, such asquestion answering, started to rely heavily on the combination of neural retrievers andreaders. Retrieval is typically performed over a large textual knowledge base whichrequires significant memory and compute resources, especially when scaled up. OnHotpotQA we explore various filtering & splitting criteria. Primarily, we systematicallyinvestigate reducing the size of the KB index by means of dimensionality (sparse randomprojections, PCA, autoencoders) and numerical precision reduction.Our results show that PCA is an easy solution that requires very little data and is onlyslightly worse than autoencoders, which are less stable. All methods are sensitive to pre-and post-processing and data should always be centered and normalized both before andafter dimension reduction. Finally, we show that it is possible to combine PCA withusing 1bit per dimension. Overall we achieve (1) 100× compression with 75%, and (2)24× compression with 92% original retrieval performance.
ecently neural network based approaches to knowledge-intensive NLP tasks, such asquestion answering, started to rely heavily on the combination of neural retrievers andreaders. Retrieval is typically performed over a large textual knowledge base whichrequires significant memory and compute resources, especially when scaled up. OnHotpotQA we explore various filtering & splitting criteria. Primarily, we systematicallyinvestigate reducing the size of the KB index by means of dimensionality (sparse randomprojections, PCA, autoencoders) and numerical precision reduction.Our results show that PCA is an easy solution that requires very little data and is onlyslightly worse than autoencoders, which are less stable. All methods are sensitive to pre-and post-processing and data should always be centered and normalized both before andafter dimension reduction. Finally, we show that it is possible to combine PCA withusing 1bit per dimension. Overall we achieve (1) 100× compression with 75%, and (2)24× compression with 92% original retrieval performance.
| Ryanize bib | 2023 |
| ÚFAL Bilingual scientific abstracts corpus | 2022 |
datacode
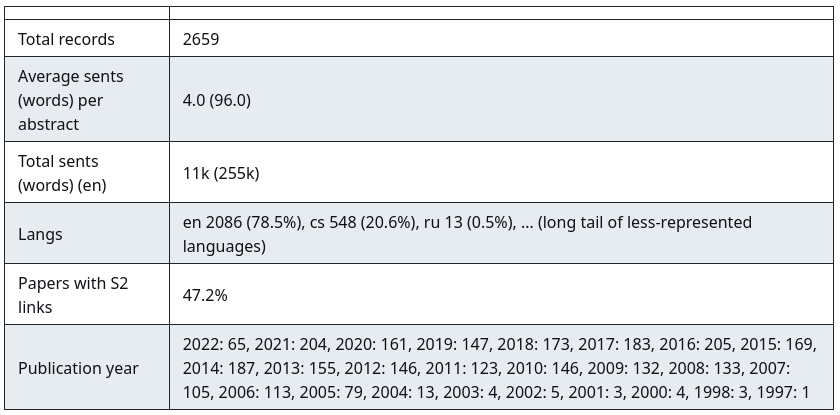
This is a parallel corpus of Czech and mostly English abstracts of scientific papers and presentations published by authors from the Institute of Formal and Applied Linguistics, Charles University in Prague. For each publication record, the authors are obliged to provide both the original abstract (in Czech or English), and its translation (English or Czech) in the internal Biblio system. The data was filtered for duplicates and missing entries, ensuring that every record is bilingual. Additionally, records of published papers which are indexed by SemanticScholar contain the respective link. The dataset was created from September 2022 image of the Biblio database and is stored in JSONL format, with each line corresponding to one record.
This is a parallel corpus of Czech and mostly English abstracts of scientific papers and presentations published by authors from the Institute of Formal and Applied Linguistics, Charles University in Prague. For each publication record, the authors are obliged to provide both the original abstract (in Czech or English), and its translation (English or Czech) in the internal Biblio system. The data was filtered for duplicates and missing entries, ensuring that every record is bilingual. Additionally, records of published papers which are indexed by SemanticScholar contain the respective link. The dataset was created from September 2022 image of the Biblio database and is stored in JSONL format, with each line corresponding to one record.
| Artefact Retrieval: Overview of NLP Models with Knowledge Base Access | AKBC CSKB 2021 |
paper
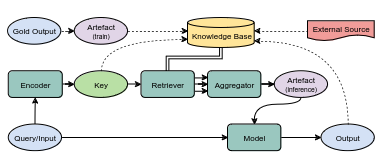
Many NLP models gain performance by having access to a knowledge base. A lot of research has been devoted to devising and improving the way the knowledge base is accessed and incorporated into the model, resulting in a number of mechanisms and pipelines. Despite the diversity of proposed mechanisms, there are patterns in the designs of such systems. In this paper, we systematically describe the typology of *artefacts* (items retrieved from a knowledge base), retrieval mechanisms and the way these artefacts are *fused* into the model. This further allows us to uncover combinations of design decisions that had not yet been tried. Most of the focus is given to language models, though we also show how question answering, fact-checking and knowledgable dialogue models fit into this system as well. Having an abstract model which can describe the architecture of specific models also helps with transferring these architectures between multiple NLP tasks.
Many NLP models gain performance by having access to a knowledge base. A lot of research has been devoted to devising and improving the way the knowledge base is accessed and incorporated into the model, resulting in a number of mechanisms and pipelines. Despite the diversity of proposed mechanisms, there are patterns in the designs of such systems. In this paper, we systematically describe the typology of *artefacts* (items retrieved from a knowledge base), retrieval mechanisms and the way these artefacts are *fused* into the model. This further allows us to uncover combinations of design decisions that had not yet been tried. Most of the focus is given to language models, though we also show how question answering, fact-checking and knowledgable dialogue models fit into this system as well. Having an abstract model which can describe the architecture of specific models also helps with transferring these architectures between multiple NLP tasks.
| Leveraging Neural Machine Translation for Word Alignment | PBML 116 |
papercode
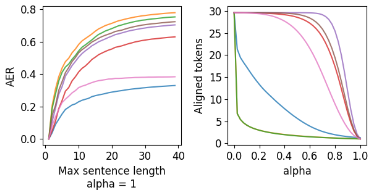
The most common tools for word-alignment rely on a large amount of parallel sentences,which are then usually processed according to one of the IBM model algorithms. The trainingdata is, however, the same as for machine translation (MT) systems, especially for neural MT(NMT), which itself is able to produce word-alignments using the trained attention heads. Thisis convenient because word-alignment is theoretically a viable byproduct of any attention-basedNMT, which is also able to provide decoder scores for a translated sentence pair.We summarize different approaches on how word-alignment can be extracted from align-ment scores and then explore ways in which scores can be extracted from NMT, focusing oninferring the word-alignment scores based on output sentence and token probabilities. Wecompare this to the extraction of alignment scores from attention. We conclude with aggregat-ing all of the sources of alignment scores into a simple feed-forward network which achievesthe best results when combined alignment extractors are used.
The most common tools for word-alignment rely on a large amount of parallel sentences,which are then usually processed according to one of the IBM model algorithms. The trainingdata is, however, the same as for machine translation (MT) systems, especially for neural MT(NMT), which itself is able to produce word-alignments using the trained attention heads. Thisis convenient because word-alignment is theoretically a viable byproduct of any attention-basedNMT, which is also able to provide decoder scores for a translated sentence pair.We summarize different approaches on how word-alignment can be extracted from align-ment scores and then explore ways in which scores can be extracted from NMT, focusing oninferring the word-alignment scores based on output sentence and token probabilities. Wecompare this to the extraction of alignment scores from attention. We conclude with aggregat-ing all of the sources of alignment scores into a simple feed-forward network which achievesthe best results when combined alignment extractors are used.
| Sentence Ambiguity, Grammaticality and Complexity Probes | BlackboxNLP 2022 |
papercode
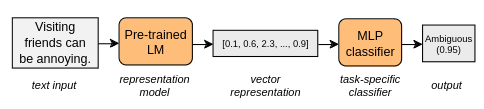
It is unclear whether, how and where large pre-trained language models capture subtle linguistic traits like ambiguity, grammaticality and sentence complexity. We present results of automatic classification of these traits and compare their viability and patterns across representation types. We demonstrate that template-based datasets with surface-level artifacts should not be used for probing, careful comparisons with baselines should be done and that t-SNE plots should not be used to determine the presence of a feature among dense vectors representations. We also show how features might be highly localized in the layers for these models and get lost in the upper layers.
It is unclear whether, how and where large pre-trained language models capture subtle linguistic traits like ambiguity, grammaticality and sentence complexity. We present results of automatic classification of these traits and compare their viability and patterns across representation types. We demonstrate that template-based datasets with surface-level artifacts should not be used for probing, careful comparisons with baselines should be done and that t-SNE plots should not be used to determine the presence of a feature among dense vectors representations. We also show how features might be highly localized in the layers for these models and get lost in the upper layers.
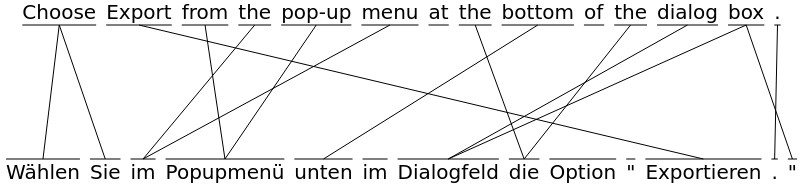
| Slow Align Displayer | 2020 |
| Enabling Outbound Machine Translation | Bachelor thesis 2020 |
linkcode
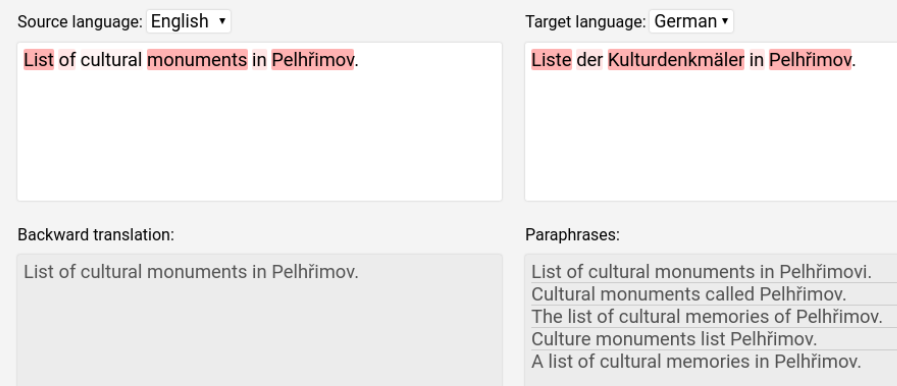
It is not uncommon for Internet users to have to produce text in aforeign language they have very little knowledge of and are unable to verify thetranslation quality. We call the task “outbound translation” and explore it byintroducing an open-source modular system Ptakopět. Its main purpose is toinspect human interaction with machine translation systems enhanced by ad-ditional subsystems, such as backward translation and quality estimation. Wefollow up with an experiment on (Czech) human annotators tasked to producequestions in a language they do not speak (German), with the help of Ptakopět.We focus on three real-world use cases (communication with IT support, describ-ing administrative issues and asking encyclopedic questions) from which we gaininsight into different strategies users take when faced with outbound translationtasks. Round trip translation is known to be unreliable for evaluating MT sys-tems but our experimental evaluation documents that it works very well for users,at least on MT systems of mid-range quality.
It is not uncommon for Internet users to have to produce text in aforeign language they have very little knowledge of and are unable to verify thetranslation quality. We call the task “outbound translation” and explore it byintroducing an open-source modular system Ptakopět. Its main purpose is toinspect human interaction with machine translation systems enhanced by ad-ditional subsystems, such as backward translation and quality estimation. Wefollow up with an experiment on (Czech) human annotators tasked to producequestions in a language they do not speak (German), with the help of Ptakopět.We focus on three real-world use cases (communication with IT support, describ-ing administrative issues and asking encyclopedic questions) from which we gaininsight into different strategies users take when faced with outbound translationtasks. Round trip translation is known to be unreliable for evaluating MT sys-tems but our experimental evaluation documents that it works very well for users,at least on MT systems of mid-range quality.
Miscellaneous
I'm currently advised by Mrinmaya Sachan at LRE lab and Menna El-Assady at IVIA lab. Previously during my bachelor's and master's I was advised by Dietrich Klakow, and Ondřej Bojar. In 2023 I got to intern at Amazon Translate. I had the privilige to supervise Yijie Tong, Haokun He, Abhinav Kumar, and David Gu.
In my free time I'm interested in veganism, electric guitar, {video,board}games, and literature.
Talks
I enjoy socializing and am grateful to have been invited to give the following talks:
- Prudent MT Evaluation at Cardiff NLP Seminars (2025), Google Translate (2024)
- Token(s) of Appreciation for BPE at MT Marathon (2024)
- ESA and ESAAI at Microsoft Translate (2024)
- How we solved tokenization but got it wrong at ZurichNLP Meetup #9 (2024)
- Quality and Quantity of Machine Translation References for Automated Metrics at IST/Unbabel seminar (2024)
- Poor Man's Quality Estimation at IST/Unbabel seminar (2023)